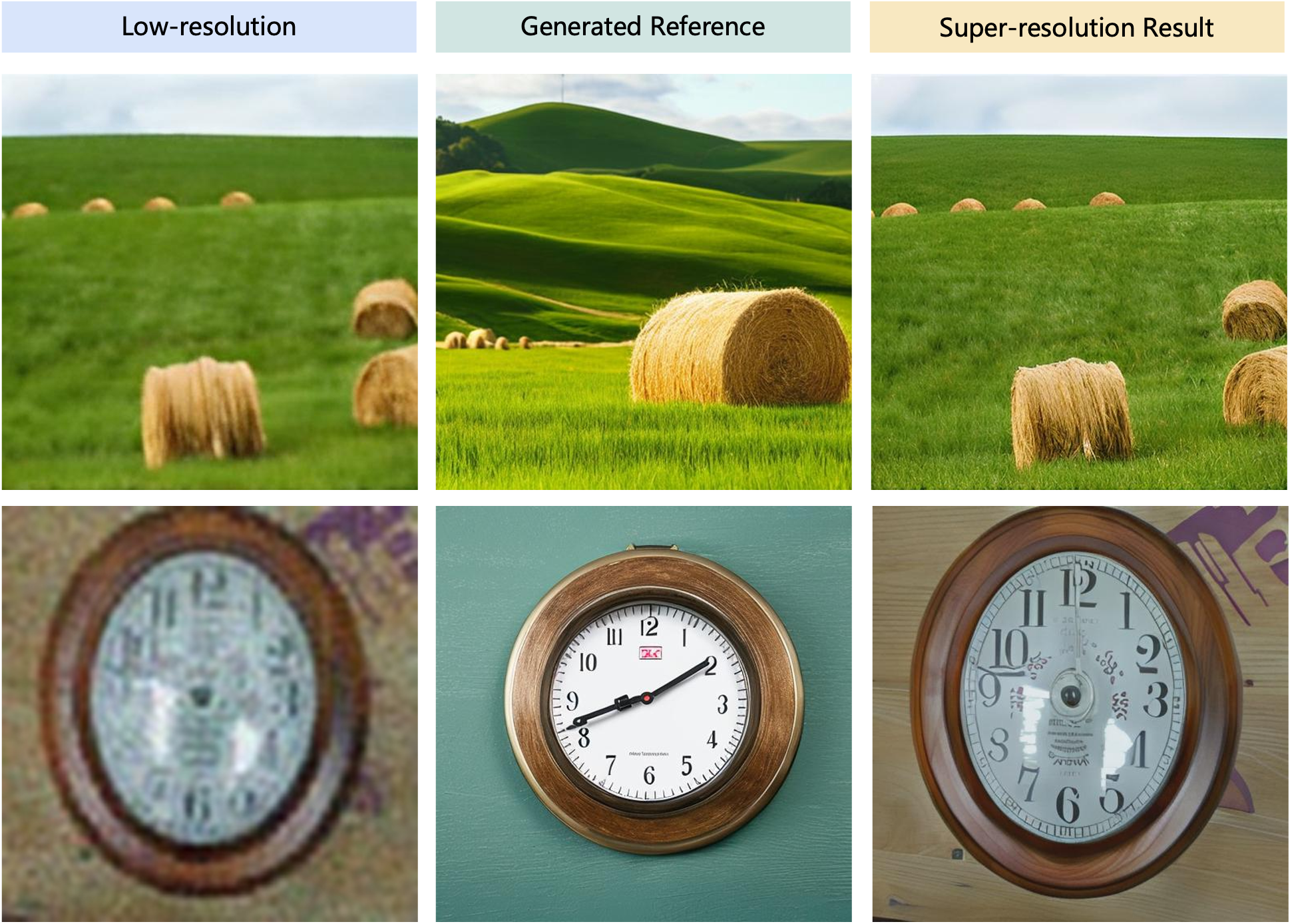
Comparsions (using your mouse as magnifier🔍)
Enriched by a comprehensive understanding of scene information, CoSeR excels in enhancing high-quality
texture details. As demonstrated in the first and second rows, our results exhibit significantly clearer and
more realistic fur and facial features in the animals. Similarly, in the third and fourth rows,
our method adeptly reconstructs realistic textures such as the anemone tentacles and succulent leaves—achievements
unmatched by other methods. Particularly, our model's cognitive capabilities enable the recovery of semantic details almost
lost in low-resolution inputs. Notably, in the first row, only our model successfully restores the dhole's eyes, while in
the fifth row, only our method can reconstruct the sand within the hourglass.
More comparsions
More comparsions on real-world or blind degradation images
Method
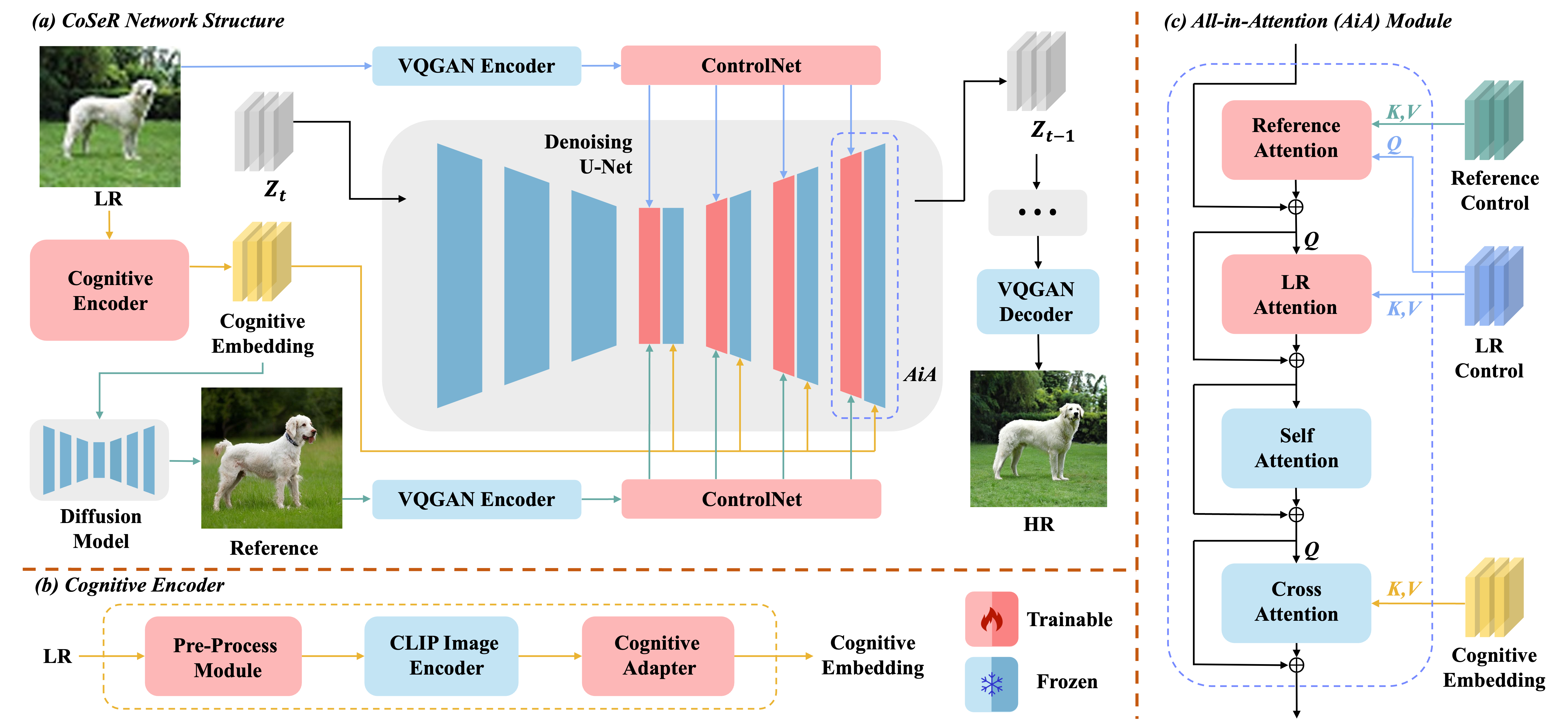
Our CoSeR employs a dual-stage process for restoring LR images. Initially, we develop a cognitive encoder
to conduct a thorough analysis of the image content, conveying the cognitive embedding to the diffusion model.
This enables the activation of pre-existing image priors within the pre-trained Stable Diffusion model,
facilitating the restoration of intricate details. Additionally,
our approach utilizes cognitive understanding to generate high-fidelity reference images that closely align with the input semantics.
These reference images serve as auxiliary information, contributing to the enhancement of super-resolution results.
Ultimately, our model simultaneously applies three conditional controls to the pre-trained Stable Diffusion model: the LR image, cognitive embedding, and reference image.
Explanations for using the cognitive embedding
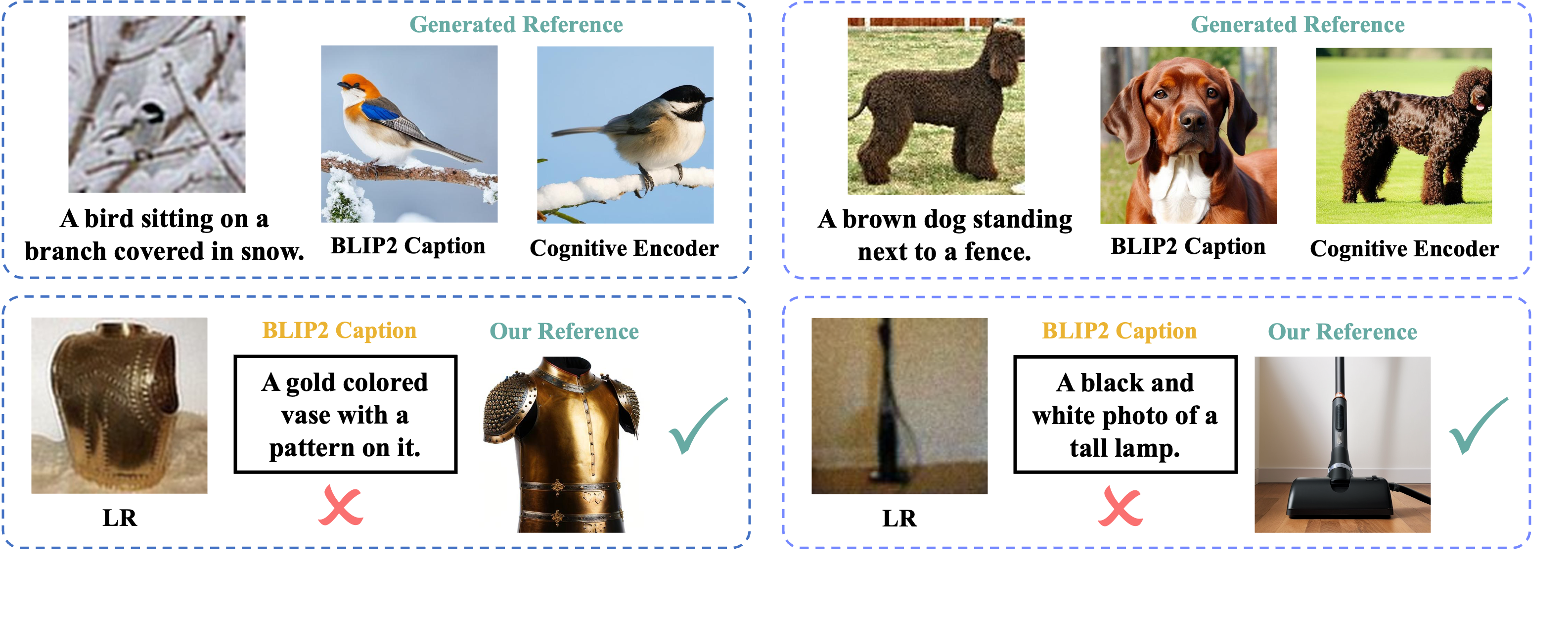
We choose to utilize the feature embedding for the cognition process rather than directly generating a caption from LR for several compelling reasons.
Firstly, although guided by language embedding, our cognitive embedding retains fine-grained image features,
proving advantageous in generating reference images with high semantic similarity.
In the first row of the figure above, we show the BLIP2 captions generated from LR images.
They fail to identify the precise taxon, color, and texture of the animals,
leading to suboptimal generations compared to our cognitive adapter.
Secondly, pre-trained image caption models may produce inaccurate captions for LR images due to disparities in the input distribution.
In contrast, our cognitive adapter is more robust for LR images, shown in the second row of the figure above.
Thirdly, employing a pre-trained image caption model requires a substantial number of parameters, potentially reaching 7B. In contrast, our cognitive adapter is significantly lighter,
with only 3% parameters, resulting in favorable efficiency.